Screen to Screen Navigation Understanding with AI
Current AI agents for automated UI testing have an expensive problem: they make LLM calls at every single step to decide what to do next. Most agents cache simple input-output pairs, but they don’t build any understanding of the overall application structure. This leads to high API costs, slow execution, and inefficient navigation.
What if we could flip this approach? Instead of real-time decision making, what if we pre-computed the entire app’s navigation structure from manual testing recordings? Could this comprehensive knowledge base provide better caching than simple input-output storage? Could it reduce the cost of agentic app testing and make navigation faster? A tool that not only maps every screen connection but also understands the context and user intent behind each transition?
 The main interface of the navigation analysis system
The main interface of the navigation analysis system
That’s exactly what I built using Microsoft’s Omniparser and Google’s Gemini LLM. I tested it by analyzing the complete navigation flow of the Rapido customer app, but the approach can be applied to any website, desktop, or mobile application.
Processing Pipeline
1. Video Frame Extraction
Endpoint: POST /extract_video_frames/
Intelligent video processing that automatically identifies key moments:
Algorithm Details:
- Frame Sampling: Processes at most 5 FPS regardless of video FPS
- Change Detection: Uses histogram correlation and MSE on downsampled frames
- Quality Preservation: Outputs full-resolution frames despite optimized processing
Configuration:
{
"sensitivity": 0.3, // 0.1-1.0 (lower = more sensitive)
"min_time_gap": 0.5 // Minimum seconds between extractions
}
2. Frame Management
# Get extracted frames
frames = requests.get(f'/extractions/{extraction_id}/frames/').json()
# Select frames for processing
requests.post(f'/extractions/{extraction_id}/select_frames/', json={
"frame_ids": [1, 3, 5, 7, 9],
"action": "keep" # or "delete"
})
3. UI Element Detection with OmniParser-v2
OmniParser is a screen parsing tool to convert general GUI screen to structured elements like icons, text and their bounding boxes.
# Process selected frames with Omniparser
requests.post(f'/extractions/{extraction_id}/process_selected/', json={
"batch_size": 4
})
4. Screen Analysis with Gemini
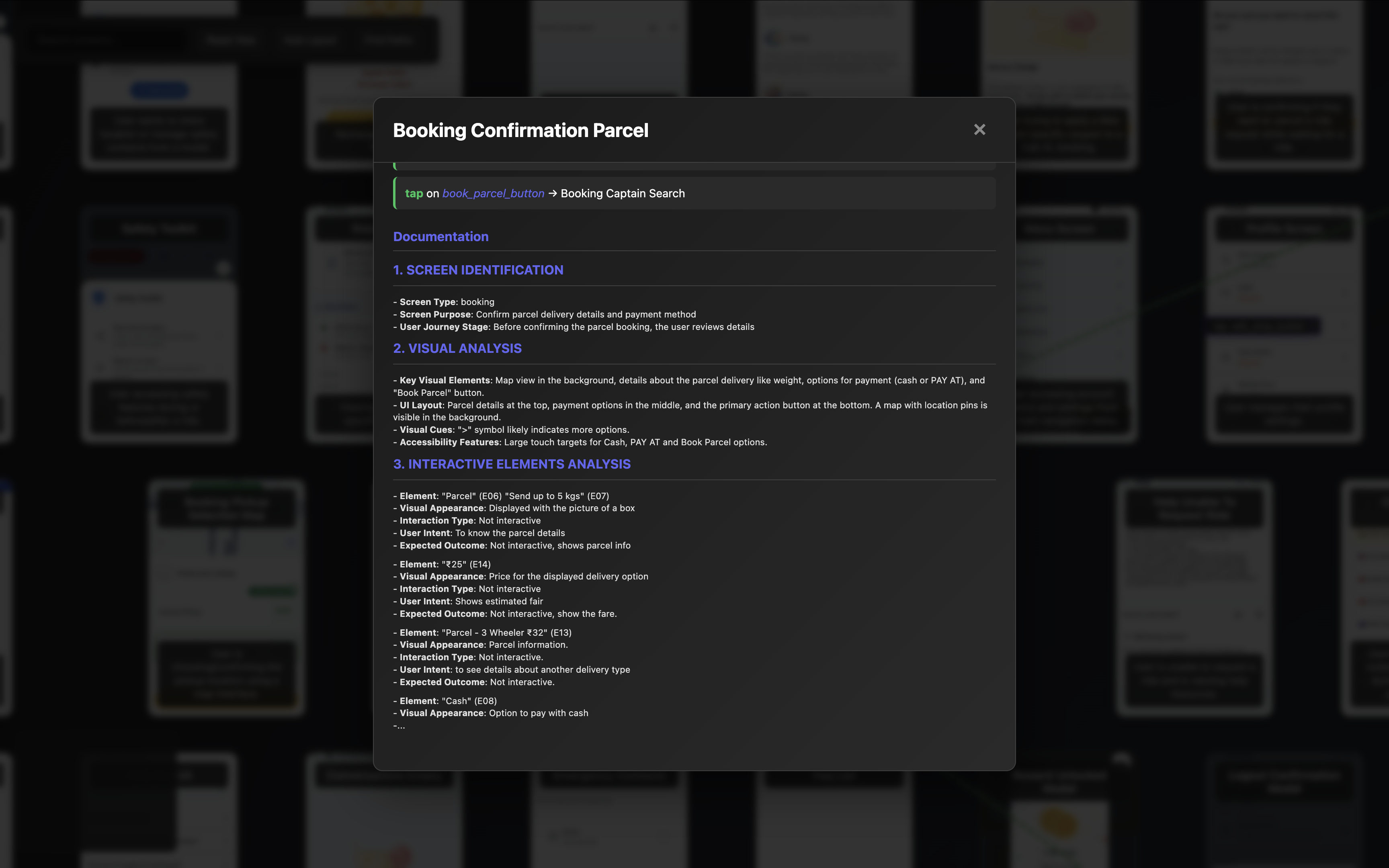 AI generated Screen description
AI generated Screen description
The system uses a sophisticated prompt template that analyzes each screen across 7 dimensions:
- Screen Identification: Type, purpose, and user journey stage
- Visual Analysis: Layout, colors, accessibility features
- Interactive Elements: Function and expected outcomes for each element
- Screen Transitions: Possible navigation paths and conditions
- Context & State: Required data and error states
- Knowledge Base Entry: Structured data for machine consumption
- Questions & Uncertainties: Areas needing clarification
Endpoint: POST /extractions/{id}/knowledge_base/
Example Analysis Output:
### 1. SCREEN IDENTIFICATION
- **Screen Type**: registration_final_step
- **Screen Purpose**: User completing profile setup
- **User Journey Stage**: End of onboarding flow
### 6. KNOWLEDGE BASE ENTRY
SCREEN: registration_final_step
CONTEXT: User completing profile setup in onboarding
ELEMENTS: name_input, gender_selection, whatsapp_toggle, next_button
TRANSITIONS:
- tap: next_button → main_dashboard (condition: name_filled AND gender_selected)
- swipe: back_gesture → previous_registration_step
AUTO_TRANSITIONS:
- form_completion → welcome_screen (timing: immediate)
NOTES: Final onboarding step, critical for user activation
5. AI-Powered Cleanup
Endpoint: POST /extractions/{id}/knowledge_base/cleanup/
Used Reasoning model to:
- Standardize naming: Convert to snake_case conventions
- Deduplicate screens: Identify and merge similar screens
- Fix transitions: Map target screens to correct standardized names
- Enhance quality: Add missing context and fix inconsistencies
6. Final Data Structure
Data Structure:
[
{
"screen": "booking_pickup_selection",
"context": "User selecting pickup location for ride booking",
"elements": [
"search_input",
"map_view",
"location_suggestions",
"confirm_button"
],
"transitions": [
{
"trigger": "tap",
"element": "confirm_button",
"target": "booking_destination_selection",
"condition": "location_selected"
}
],
"auto_transitions": [
{
"trigger": "location_detected",
"target": "booking_confirmation",
"timing": "3_seconds"
}
],
"notes": "Critical step in booking flow"
},
{
// ... other screens
}
]
Graph-Based Path Discovery
The system constructs a complete navigation graph from knowledge base entry and uses pathfinding algorithms to discover all possible routes between any two screens.
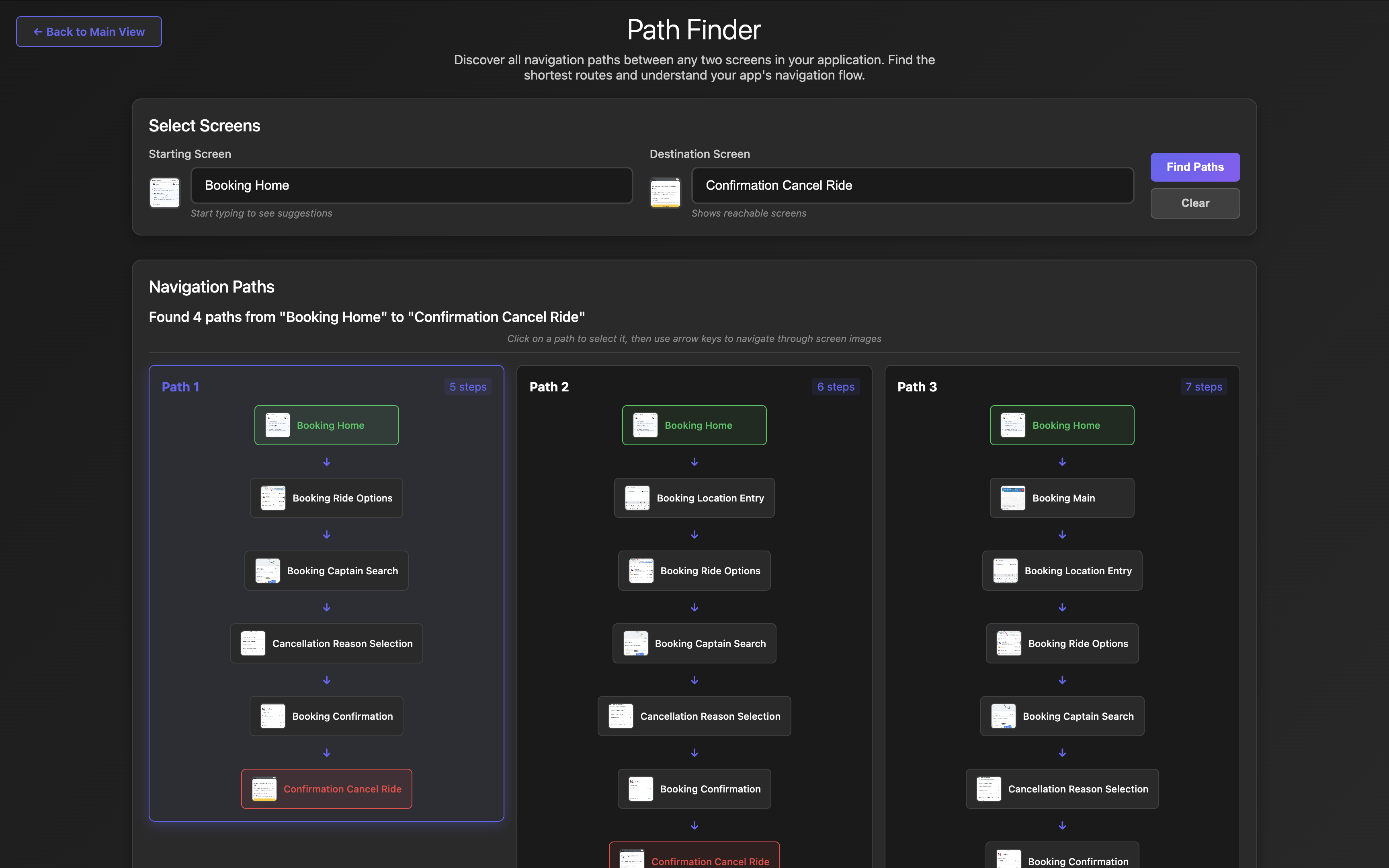 Path Finding search showing results from “Booking Home” screen to “Confirm Cancel Ride” screen
Path Finding search showing results from “Booking Home” screen to “Confirm Cancel Ride” screen
Each path includes interactive screenshots, transition metadata, and step-by-step navigation instructions.
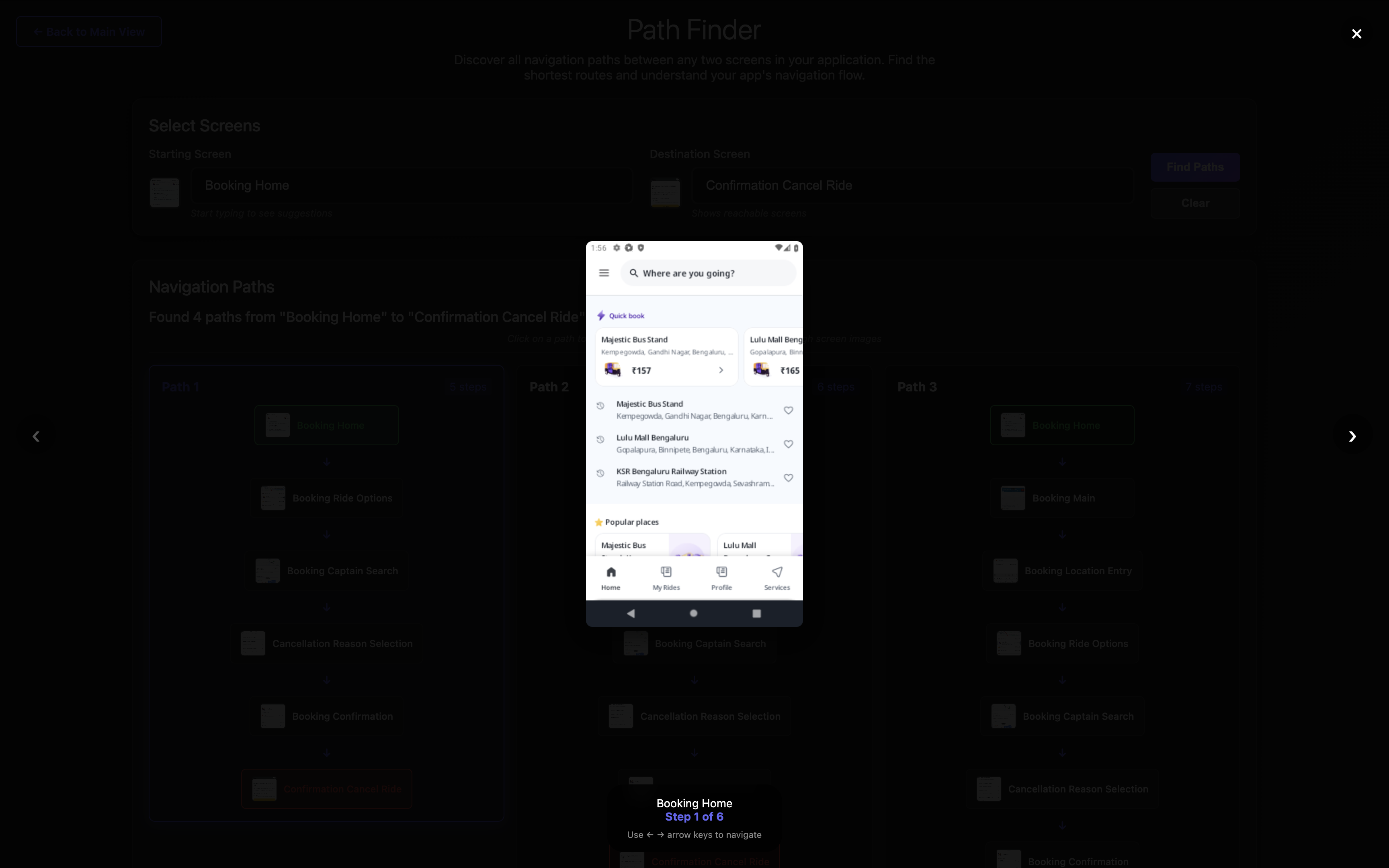
Step 1: Source Screen is Booking Home
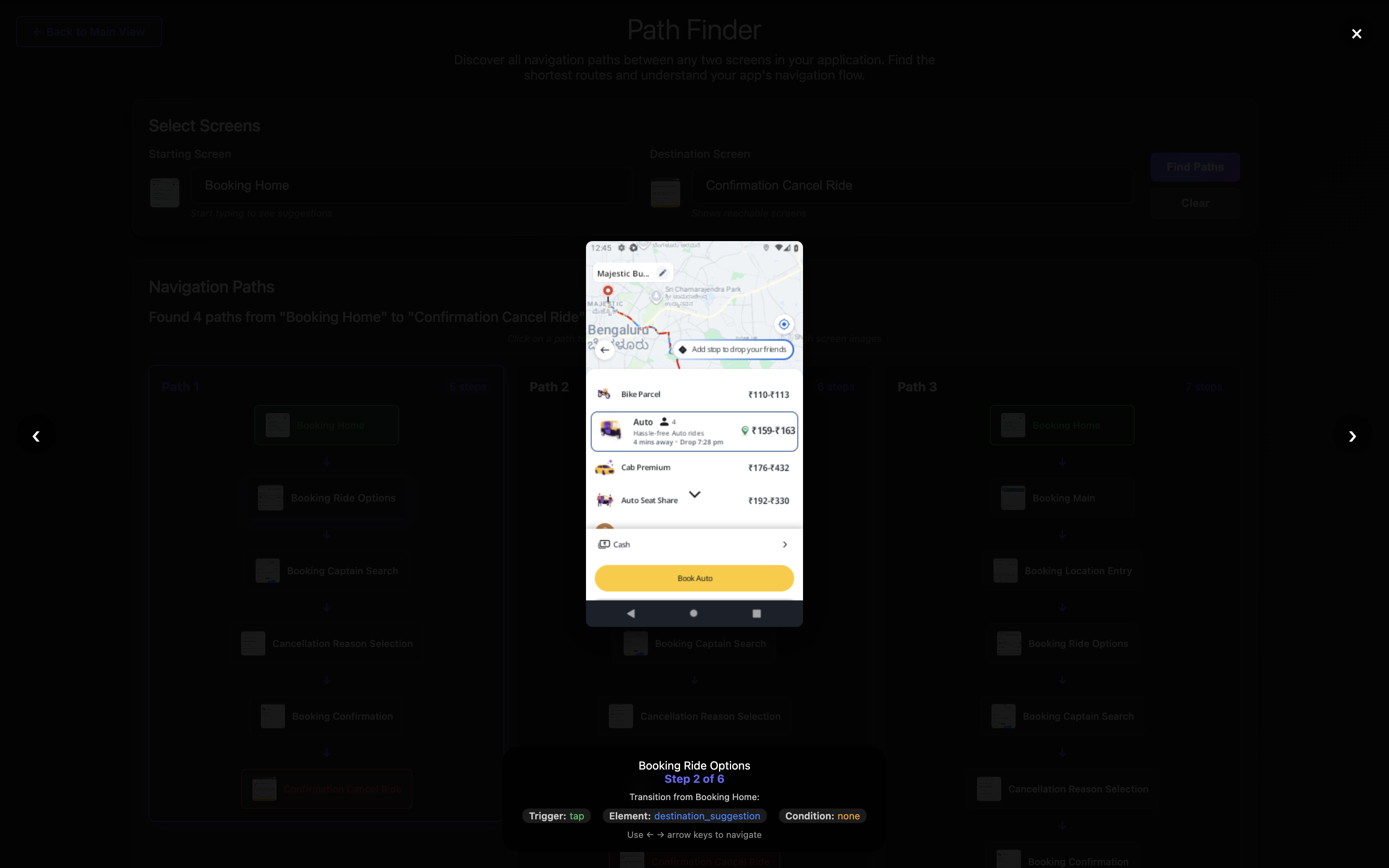
Step 2: Tap destination_search to reach Booking Ride Options
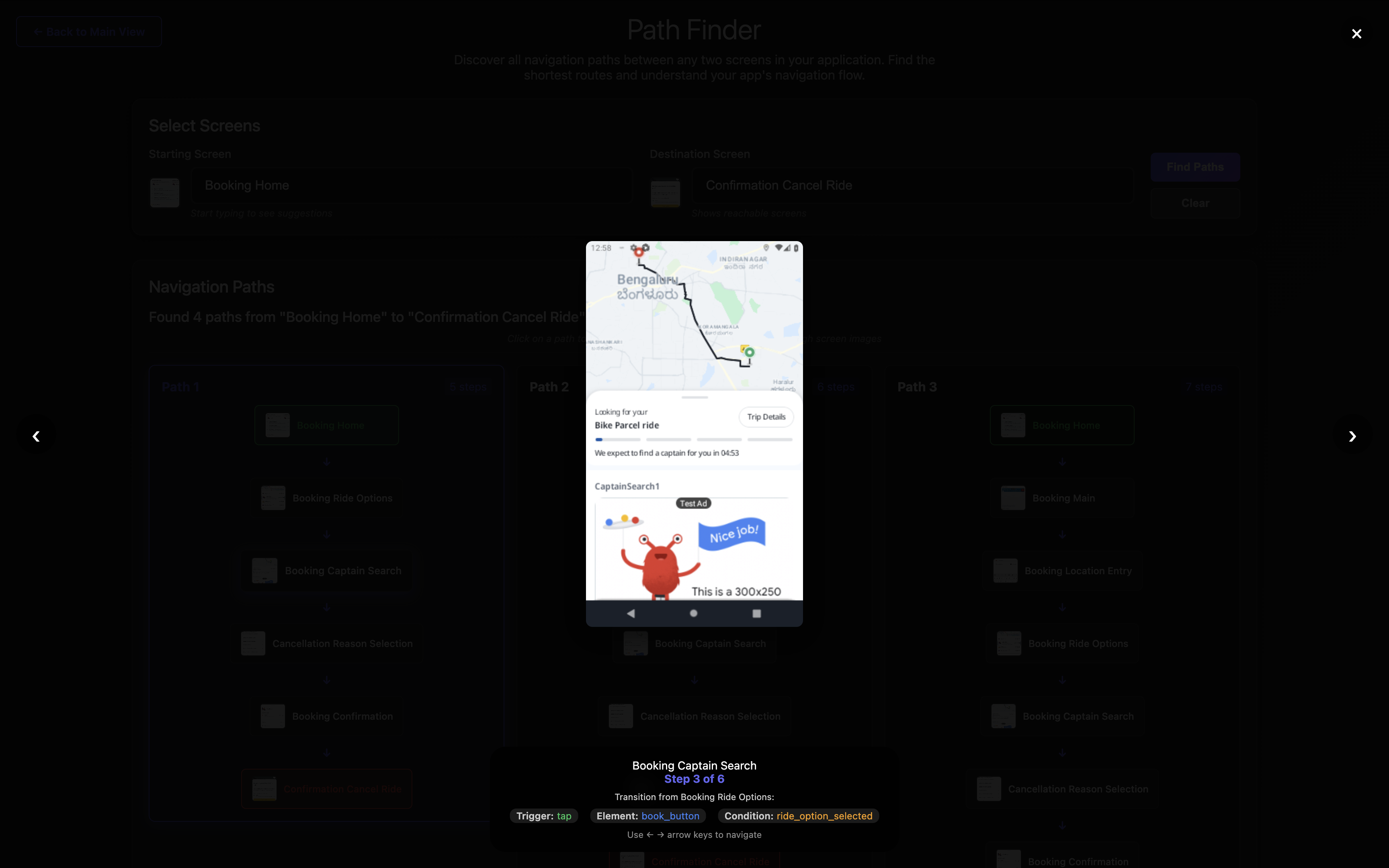
Step 3: Tap book button to reach Captain Search
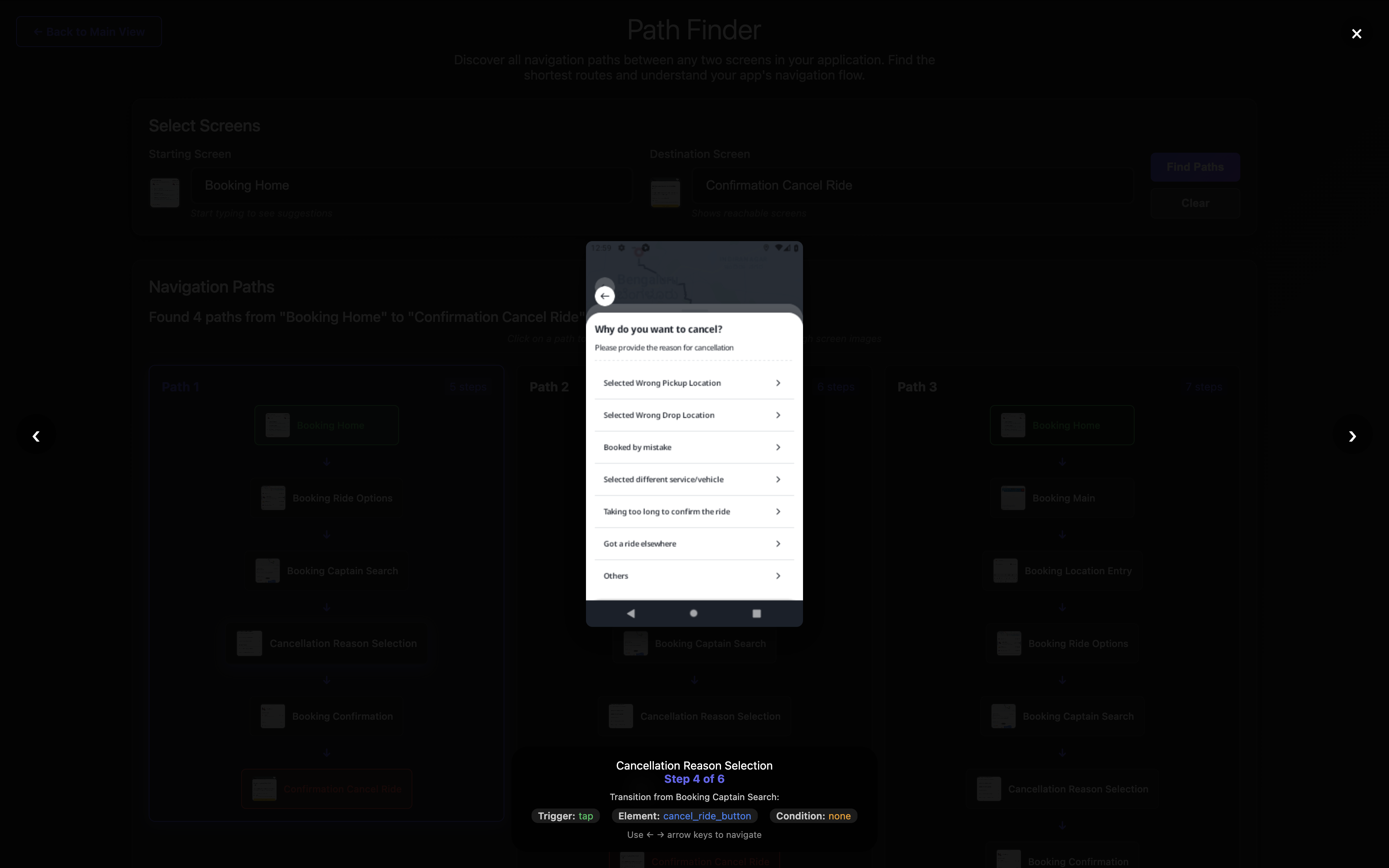
Step 4: Tap cancel_ride to reach Cancellation Reason Selection
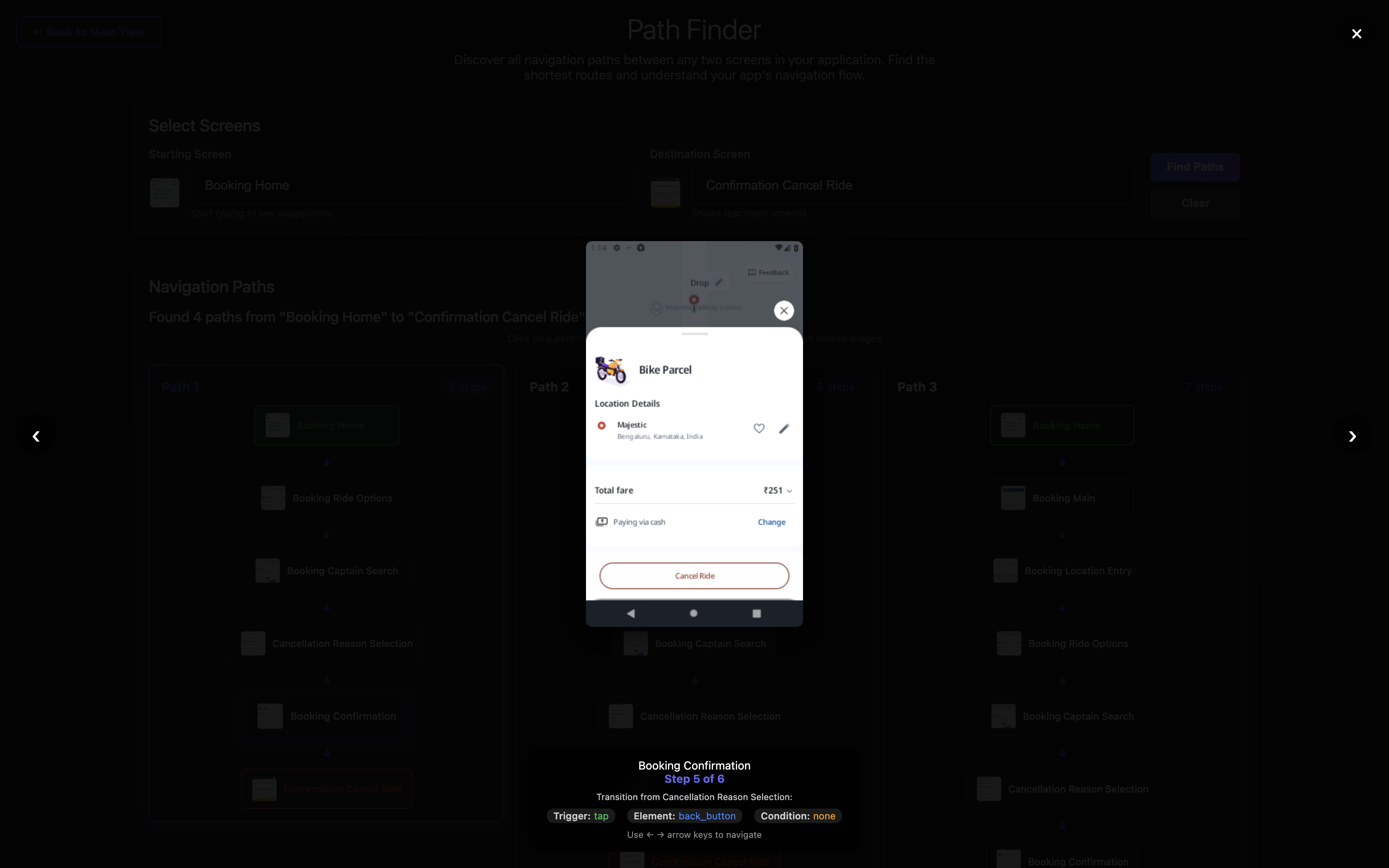
Step 5: Tap back_button to reach Booking Confirmation
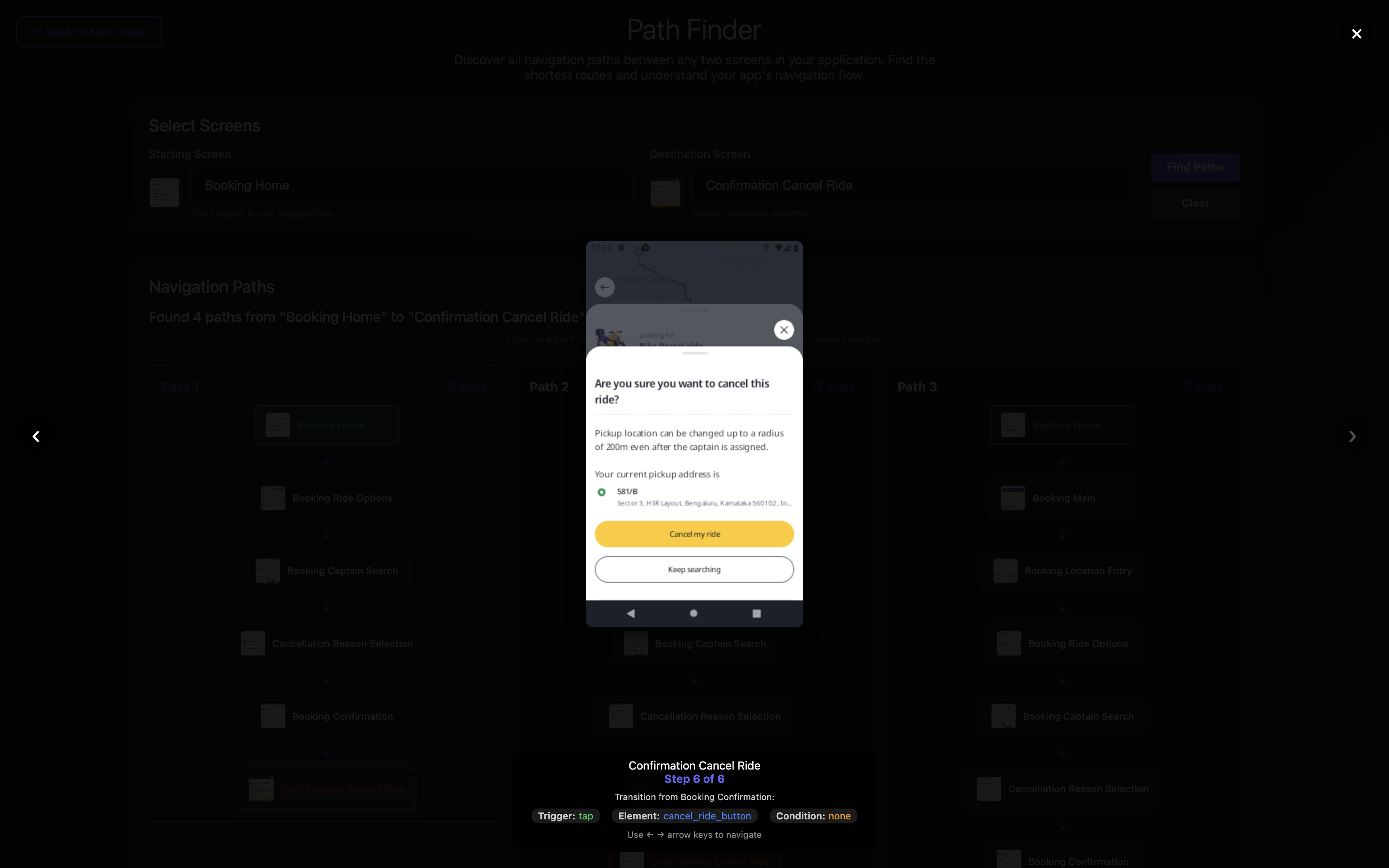
Step 6: Tap cancel_ride_button to reach Confirm Cancel Ride
Building Navigation Intelligence for Autonomous Systems
Original Intent: Knowledge Base for AI Agents
The initial vision was ambitious: create a comprehensive knowledge base that AI agents could use to understand and navigate websites and mobile applications autonomously. The idea was that with detailed screen-by-screen analysis and transition mapping, AI agents could plan complex multi-step navigation sequences to accomplish user goals.
The Theory: An AI agent could query the navigation knowledge base to understand:
- “What screens exist in this app?”
- “How do I get from the home screen to the checkout?”
- “What are all the possible paths to cancel a booking?”
- “What elements should I interact with to complete a purchase?”
The Reality: AI Agents and Immediate Action Bias
However, during testing with various AI agents, an interesting pattern emerged. AI agents consistently focused on immediate, first-step actions rather than using the comprehensive navigation knowledge for long-term planning.
When presented with the complete navigation graph and detailed pathfinding capabilities, AI agents would:
- ✅ Use screen context to understand the current state
- ✅ Identify interactive elements on the present screen
- ✅ Determine the next logical step in a workflow
- ❌ Rarely plan multi-step sequences using the full path knowledge
- ❌ Seldom leverage alternative routes when primary paths failed
- ❌ Infrequently use the pathfinding for complex goal achievement
The sophisticated pathfinding and navigation intelligence that seems so valuable for human analysts may be less immediately useful for AI agents than originally envisioned.
Future Uncertainty: Where Does This Lead?
This disconnect between the tool’s capabilities and AI agent usage patterns leaves me uncertain about its future direction.
Results and Implications
After testing with the Rapido customer app (200+ screens):
Technical Achievements:
- 200+ screens analyzed from user session recordings
- 500+ navigation transitions mapped automatically
- Sub-millisecond pathfinding between any two screens